

















連日ニュースを賑わすChatGPTなどの生成AIですが、最近「AIが学習するためのデータを使い果たしつつある」というスタンフォード大学の研究報告が世界的な議論を呼んでいます。「AIは放っておいても勝手に賢くなり続けるのではないか?」と漠然と捉えていた方にとって、AIの成長限界を示唆するこのニュースは非常に難解で、かつ不気味に響くかもしれません。
本記事では、この「データ枯渇(Data Wall)」と呼ばれる現象がなぜ起きているのか、そしてそれが私たちの日常的なインターネット利用や仕事の価値にどのような根本的な変化をもたらすのかを、論理的かつ具体的に解き明かします。
人間の言葉が尽きる日。AI学習用データの枯渇問題とは
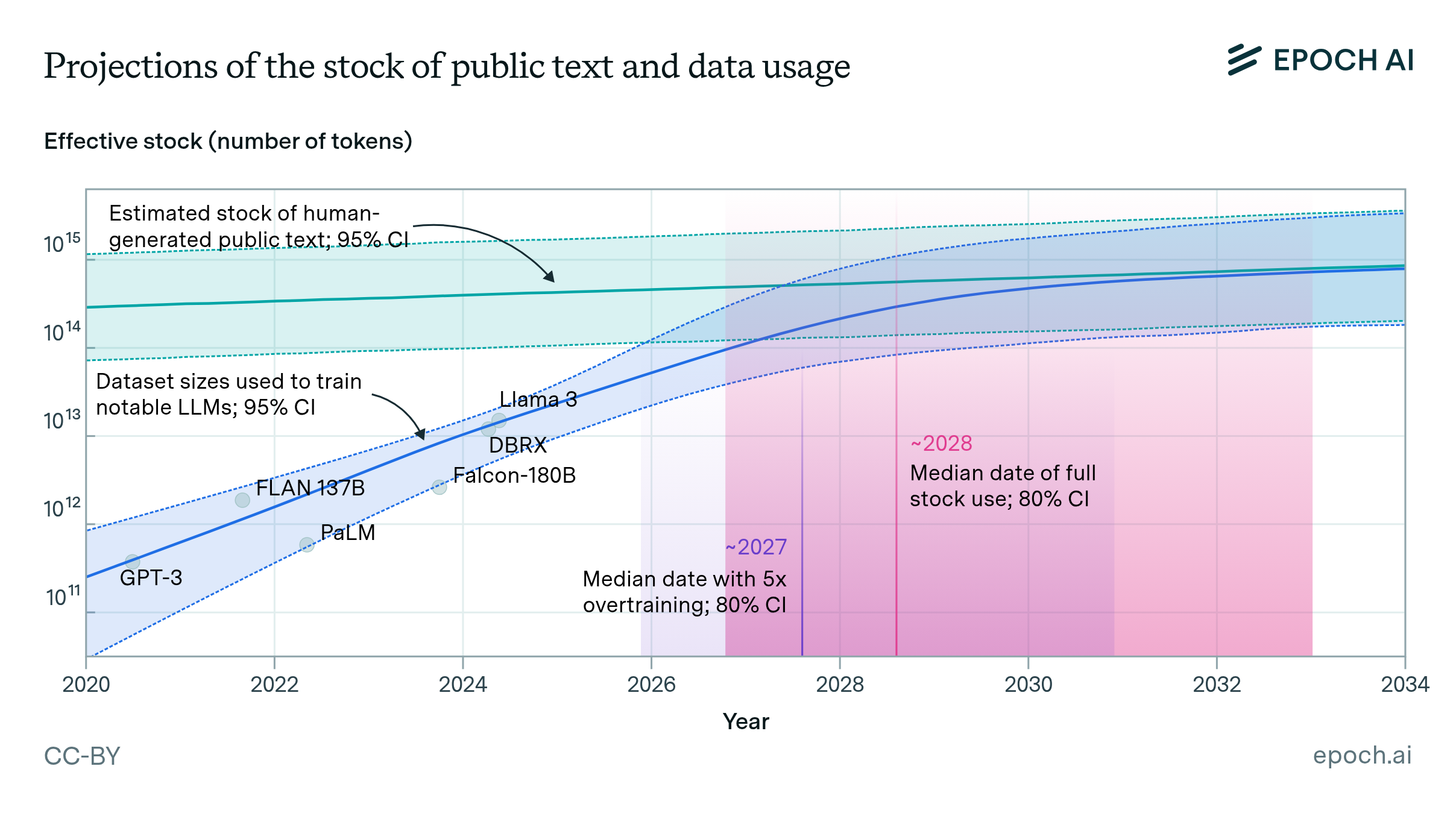
現在、スタンフォード大学が発表する権威あるレポート「AI Index Report」や、関連する研究機関(Epoch AIなど)の予測データにおいて、最も深刻な懸念として挙げられているのが「高品質な言語データの枯渇」です。これまでのAIの驚異的な進化は、革新的なアルゴリズムの発明だけでなく、インターネット上に存在する膨大なテキストデータを「力技で全て読み込ませる」ことによって実現されてきました。
AI開発企業は、Wikipedia、ニュース記事、出版された書籍、そして私たちがSNSや掲示板に書き込んだ無数のテキストをクローラーと呼ばれるプログラムでかき集め、AIの学習に利用してきました。しかし、問題は「インターネット上の高品質なテキストの総量には限界がある」という事実です。
研究チームの分析によれば、プロのライターや専門家、あるいは人間がしっかりと推敲して書いた「高品質なデータ(High-quality language data)」は、早ければ2026年前後にはすべてAIに読み込まれ、学習用に使い果たされると予測されています。地球上の人間が新しくテキストを生み出すスピードよりも、AIがデータを飲み込むスピードの方が圧倒的に速いため、AIは「次に読むべき新しい良質な教科書」を失う危機に直面しているのです。これが、テクノロジー業界で危惧されている「データ枯渇問題」の正体です。
模倣の限界。質の低い「AI生成データ」が引き起こすモデル崩壊
このニュースに触れたとき、多くの方が「データが足りないなら、AI自身に新しい文章を作らせて、それを学習させれば無限に賢くなるのでは?」という疑問を抱くはずです。しかし、このアプローチには致命的な欠陥が存在します。それが「モデル崩壊(Model Collapse)」と呼ばれる現象です。
AIが生成したテキストを、別のAI(あるいは次世代のAI)が学習データとして読み込むことを繰り返すと、AIの出力品質は急速に劣化していきます。これを分かりやすく例えるなら、「コピー機のコピー」です。オリジナルの美しい書類(人間が書いた文章)をコピーする分には綺麗ですが、そのコピーを原本にしてさらにコピーし、それを何度も繰り返すと、文字は徐々にぼやけ、ノイズが混じり、最終的には真っ黒で読めない紙になってしまいます。
AIの言語モデルは、データの中にある「確率的にありふれた表現」を強調し、少数派のユニークな表現や細かなニュアンスを切り捨てる傾向があります。そのため、AI同士で学習を繰り返すと、文章から人間らしい多様性や論理的な深みが失われ、事実と異なる幻覚(ハルシネーション)や、無意味で均質な文章ばかりが出力されるようになります。
つまり、AIが今後も人間を凌駕するような知能を獲得していくためには、AI自身が生み出した合成データではなく、人間が実際に経験し、思考し、感情を伴って記述した「本物の一次データ」が絶対に不可欠なのです。
人間が書いた「一次情報」の価値が劇的に高まる社会へ
高品質な学習データが枯渇していくという事実は、私たちのインターネット社会の経済構造を根底から作り変えるインパクトを持っています。最も顕著な変化は、「人間が書いたテキストの資産価値の暴騰」です。
これまで、私たちがブログやSNS、レビューサイトに書き込む文章は、プラットフォーム側が無料で収集できる「フリー素材」のように扱われてきました。しかし現在、事態は急変しています。アメリカの巨大掲示板Redditや、イーロン・マスク氏が率いるX(旧Twitter)などは、自社のプラットフォーム上にある「人間のリアルな会話データ」へのアクセス権(API)を有料化し、AI開発企業に対して年間数十億円という巨額のライセンス料を要求するようになりました。
これは、日々の生活において私たちが発信する「生の声」が、新しい時代の石油とも言える貴重な資源として取引され始めたことを意味します。今後、インターネット上の検索エンジンやメディアは、AIが自動生成した量産型のスパム記事で溢れかえることが予想されます。その結果、情報の受け手である消費者も、AI開発者も、共に「これは間違いなく人間が実体験に基づいて書いた一次情報である」と証明されたコンテンツにのみ、高い対価を払う経済圏へとシフトしていくことになります。AIが普及すればするほど、皮肉なことに「人間特有の泥臭い経験や独自の視点」の希少価値が極限まで高まる社会が到来するのです。
AI時代を生き抜くために私たちが身につけるべき「経験の発信力」
このようなデータ枯渇の時代において、私たちが個人として、あるいはビジネスパーソンとして取るべきアクションプランは明確です。それは、インターネット上で情報を発信する際、「AIでも書けるような一般的なまとめ情報」を捨てることです。
ブログ記事を書く、仕事でレポートを作成する、あるいは商品のレビューを投稿する場面を想像してください。Wikipediaの情報を整理したり、どこかのニュースサイトの受け売りを綺麗にまとめただけの文章は、すでにAIが数秒で作成できる無価値なデータへと成り下がっています。今から私たちが意識すべきは、徹底的に「自分にしか語れない一次情報」を文章に組み込むことです。
具体的には、自分が実際に足を運んで得た現場の事実、失敗から学んだ教訓、特定の専門分野における独自の考察、あるいは数字に基づいた一次データなどです。これらは、AIがウェブ上からスクレイピング(自動収集)して推測することができない、あなただけの固有の資産です。
情報発信の際は、「この記事のどこがAIには書けない部分か?」を常に自問自答してください。その意識を持ち、人間ならではの文脈や感情を伴った事実を発信し続けること。それこそが、AIに仕事や影響力を奪われることなく、むしろAI社会において最も重宝される存在になるための最強の生存戦略となります。
まとめ
スタンフォード大学の報告書が突きつけた「データ枯渇」の未来は、AIの進化が終焉を迎えるという単純な悲観論ではありません。それは、インターネット上のデータが「量の時代」から「質の時代」へと劇的に移行する歴史的な転換点です。AIのアルゴリズムがいかに高度化しようとも、その知能の源泉は私たち人間が生み出す一次情報に依存しています。無機質なAI生成コンテンツが氾濫するこれからの世界において、私たちの持つリアルな経験、独自の思考、そして人間としての「生の言葉」こそが、最も価値の高いリソースとして輝きを放つことになるのです。
【参考文献・出典元】
Stanford University – AI Index Report 2024

Epoch AI – Will we run out of data? Limits of LLM scaling based on human-generated data

コメント